
GLAM/Newsletter/October 2019/Contents/Structured Data on Wikimedia Commons report
|
|
Getting started, Tool highlights, Blog posts and presentations about SDC
How to get started with Structured Data on Wikimedia Commons?
If you are getting started with Structured Data on Wikimedia Commons, the recent workshop slides from WikidataCon should give you a quick overview of what's new and how you can edit structured data:

Structured Data on Commons tools
Since several months, it is possible to edit multilingual captions and statements on Wikimedia Commons via UploadWizard and via file pages on Wikimedia Commons. But recently, community members have also started developing various tools with which you can easily add structured data to Commons files. A few highlights below:
The ISA Tool
The ISA Tool is a multilingual, mobile-friendly tool, that makes it easy for anyone - especially beginners! - to add structured data to images on Wikimedia Commons. You can create 'tagging' campaigns and small competitions in ISA, but you can also use it for your personal workflows. Anyone can do this - no need to be an administrator or a skilled user! ISA is developed by Wiki In Africa and Eugene Egbe in collaboration with Histropedia and the Structured Data on Commons team.
-
 At various past conferences, people have organized mini-challenges with ISA.
At various past conferences, people have organized mini-challenges with ISA. -
 The ISA Tool received a WikidataCon 2019 award in the Multimedia category!
The ISA Tool received a WikidataCon 2019 award in the Multimedia category!


You can give ISA a try by adding structured data in the campaign of Quality images supported by a Wikimedia chapter: https://tools.wmflabs.org/isa/campaigns/33
AC/DC
AC/DC ("Add to Commons, Descriptive Claims") is a batch editing tool by Lucas Werkmeister. It allows for complex data modeling of sets of files, either defined by a category or by a Pagepile. This is the only batch tool right now that supports Qualifiers. Installation is simple through the Preferences Gadget menu, and it supports large and small batches of files well. For more, see commons:Help:Gadget-ACDC
-
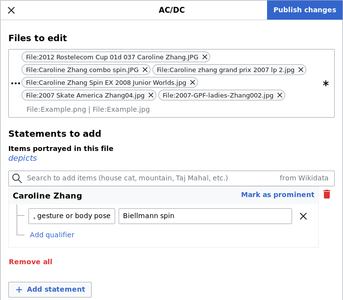 An example of the AC/DC tool in action
An example of the AC/DC tool in action

SDC
SDC is a user script developed by Magnus Manske that is similar to HotCat, allowing users to both:
- evaluate the existing structured data statements on a file page from a category or search results page and
- add a limited set of statements (currently P180 (Depicts) and P195 (Collection)). The tool only adds structured data to files on one page of a category; if a Commons category is exceptionally large and you want to add structured data to many or all files, this is not the tool for you.
PetScan integration with QuickStatements
It is now also possible to use PetScan to add structured data to files on Wikimedia Commons, through integration with QuickStatements. The process works as follows:
- Do a search on PetScan that produces a list of files as result (example: files in Category:Volkswagen T1) . For creating PetScan results for Commons files, note that:
- The Wiki needs to be set to “wikimedia” for the project, and “commons” for the language
- The namespace for files needs to be selected in the second tab.
- You will then see a small box at the top right of the file list in which you can enter statements to add to those files (example: P180:Q1819861)
- When clicking 'Start QS', you will be taken to QuickStatements in which you can then run your batch edit.
A link to PetScan from each category is coming to the commons:Template:Wikidata Infobox soon, so creation of the queries should be quite straightforward from that point.
Help welcome with data modeling!
The Wikimedia Commons community is at this moment thinking about the best ways to describe files on Wikimedia Commons with structured data. This is very new territory: there are no established ways yet to, for instance, describe the creators or locations of files.
Please help with this process by participating in the data modeling discussions at https://commons.wikimedia.org/wiki/Commons:Structured_data/Modeling and its various subpages. Examples and thoughts about GLAM files are especially welcome here.
Blog posts about Structured Data on Wikimedia Commons
The following blog posts by Keegan Peterzell outline the development process behind SDC:
- Structured Data on Commons – A Blog Series
- Structured Data on Commons, Part Two – Federated Wikibase and Multi-Content Revisions
- Structured Data on Commons, Part Three – Multilingual File Captions
- Structured Data on Commons, Part Four – Depicts statements
- Structured Data on Commons, Part Five – Other statements
Also check this blog post by Lucas Werkmeister:
Structured Data on Commons at WikidataCon 2019
Andrew Lih presented about Wikidata Commons contribution strategies for GLAM organizations and SandraF did a hands-on workshop about Structured Data on Wikimedia Commons.
Structured Data is coming to WikiConference North America
There is also a Workshop at WikiConference North America on Friday, November 8.
- Australia report
- Colombia report
- Czech Republic report
- Estonia report
- Finland report
- France report
- Indonesia report
- Malaysia report
- Netherlands report
- Norway report
- Sweden report
- UK report
- USA report
- Special story
- Structured Data on Wikimedia Commons report
- Wikipedia Library report
- Wikidata report
- Wikimedia and Libraries User Group report
- Wikisource report
- WMF GLAM report
- Calendar